
robots.txt importantisimo
ROBOTS.TXT INDEXACION :

Robots.txt
El archivo Robots.txt es un simple archivo de texto que sirve para indicarle a los robots o bots de los motores de búsqueda, encargados de rastrear e indexar los contenidos de las webs, qué secciones de nuestras webs queremos que indexen, y qué secciones queremos que omitan; es decir, que secciones y sus respectivos contenidos no queremos que se almacenen en la base de datos de contenidos de Google. Esto quiero decir que los contenidos de dichas páginas no se mostrarán en los resultados de búsqueda pero, mucha atención, aún así cabe la posibilidad (remota) de que estas páginas pueden aparecer en los resultados de búsqueda (sin título ni descripción alguna, solo mostrándose la URL).
Saber manejar este archivo es super importante para evitar diferentes problemas de indexación que evitan que obtengamos buenos resultados en Google: el contenido duplicado y la pérdida de PR en páginas administrativas (backend) por dar un par de ejemplos. Si tu sitio no tiene un archivo robots.txt, entonces el bot de Google ingresará a tu página y comenzará a indexar todo lo que se le cruce en el camino, para bien o para mal.
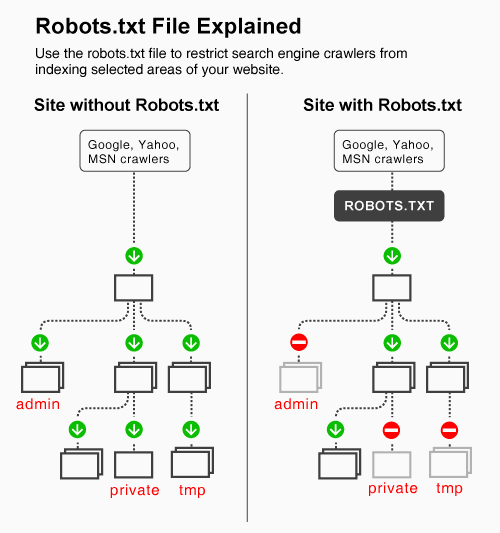
La ubicación normal del archivo robots.txt (un archivo de texto normal con instrucciones ingresadas de acuerdo a un estandar que veremos más adelante) es el root o folder principal de tu página web, donde se encuentra tu index. Por ejemplo, este es mi archivo robots.txt:
[b]User-agent: Googlebot
# Disallow all directories and files within
Disallow: /cgi-bin/
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: /directorio/
Disallow: /backup/
# Disallow all files ending with these extensions
Disallow: /*.php$
Disallow: /*.js$
Disallow: /*.inc$
Disallow: /*.css$
Disallow: /*.gz$
Disallow: /*.cgi$
Disallow: /*.wmv$
Disallow: /*.png$
Disallow: /*.gif$
Disallow: /*.jpg$
Disallow: /*.cgi$
Disallow: /*.xhtml$
Disallow: /*.php*
Disallow: */trackback*
Disallow: /*?*
Disallow: /wp-*
Allow: /wp-content/uploads/
# Disallow parsing individual post feeds, categories and trackbacks..
Disallow: */trackback/
Disallow: */feed/
Disallow: /category/*
Disallow: /page/
Disallow: /comments/
Disallow: /2006/
Disallow: /2007/
# allow google image bot to search all images
User-agent: Googlebot-Image
Allow: /*[/b]
Crear un archivo robots.txt es súper sencillo, ya que lo podemos crear en un bloc de notas común y corriente. Lo difícil es aprender a agregarle contenido adecuadamente. Los comandos utilizados dentro de este archivo son los siguientes:
* User-agent: [nombre del spider / bot de un buscador determinado]
* Disallow: [Directorio o archivo]
* Allow: [Directorio o archivo]
* Sitemap: [URL del sitemap XML de tu sitio]
El user-agent viene a ser el nombre con el que se identifica oficialmente al crawler o bot de un buscador o servicio de indexación determinado. Estos son los más comunes:
* Googlebot (Google)
* googlebot-image (Google Image)
* googlebot-mobile (Google Mobile)
* msnbot (MSN Search)
* yahoo-slurp (Yahoo)
* yahoo-mmcrawler (Yahoo MM)
* yahoo-blogs/v3.9
* teoma (Ask/Teoma)
* twiceler (Cuil)
* robozilla (Dmoz checker)
* ia_archiver (Alexa)
* baiduspider (Baidu)
Mediante el comando disallow, indicamos los archivos o directorios de nuestro blog que no queremos que sean indexados; es decir, aquellos que no queremos que aparezcan en los resultados de búsqueda de Google u otros. El comando Allow hace lo contrario.
Finalmente, mediante el comando Sitemap indicamos la URL en donde se encuentra el sitemap XML de nuestro sitio (la lista de URLs de nuestra página web, que ayuda a Google a indexar todo nuestro sitio más rápido).
Configurando el archivo robots.txt para WordPress
Mi archivo robots.txt contine indicaciones bastante específicas para el Google Bot (User-agent: Googlebot), las cuales paso a explicar a continuación:
Las siguientes líneas evitan que Google indexe los directorios que almacenan los archivos administrativos (wp-admin), la carpeta includes (wp-includes), la carpeta donde guardamos nuestros backups y cualquier otro folder en la raiz del sitio donde guardemos información que no deseamos que sea indexada.
Disallow: /cgi-bin/
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: /directorio/
Disallow: /backup/
Estas líneas evitan la indexación de archivos que terminen con estas extensiones: php, js (java scripts), inc, css (hojas de estilo), gif, jpg, png (no queremos que en los resultados de búsqueda aparezca en enlace a una imagen, esto se lo dejamos a Google images), etc.
Disallow: /*.php$
Disallow: /*.js$
Disallow: /*.inc$
Disallow: /*.css$
Disallow: /*.gz$
Disallow: /*.cgi$
Disallow: /*.wmv$
Disallow: /*.png$
Disallow: /*.gif$
Disallow: /*.jpg$
Disallow: /*.cgi$
Disallow: /*.xhtml$
Disallow: /*.php*
Disallow: */trackback*
Disallow: /wp-*
Esta línea evita la indexacion de URLs con el operador “?” (común en las URLs con resultados de búsqueda):
Disallow: /*?*
Estas líneas evitan la indexación de los feeds individuales (copia del contenido de cada post en formato para feeds), las páginas de categorías y las URLs generadas por la paginación (page 2, page 3, etc), todo con la finalidad de evitar la indexación de contenido duplicado:
Disallow: */feed/
Disallow: /category/*
Disallow: /page/
Y, finalmente, esta línea permite que bot de Google Images que indexe las imágene de la web:
User-agent: Googlebot-Image
Disallow:
Allow: /*
Ahora, si no desean molestarse en aprender este código tan fácil, les recomiendo instalar el plugin Robots-Meta para WordPress, el cual les permitirá configurar el archivo de manera sencilla y rápida.
Si no tienen un blog en WordPress pero quieren generar rápidamente un archivo robots.txt, existen algunos generadores en línea, pero yo recomiendo el que nos brinda la herramienta para webmasters de Google.
[enlace]
¿Y si tengo un blog o web pero no tengo acceso al servidor?
En este caso, podemos obtener la misma funcionalidad mediante la utilización de la meta etiqueta robots. El único inconveniente es que tendremos que personalizarla de acuerdo a la página en la cual la coloquemos, lo cual hace esta labor muy trabajosa para ser aplicada en un CMS. Sirve para páginas con poco contenido o para usuarios que sepan personalizarlas vía código PHP, por ejemplo.
La meta etiqueta robots tiene el siguiente formato:
[size=18px][b]<meta name="robots" content="robots-terms">[/b]
El contenido dentro de “robots-terms” es una lista, separada por comas, con uno o varios de los siguientes indicadores, dependiendo del caso: noindex, nofollow, all, index y follow.
* NoIndex, indica al bot que la página actual no debe ser indexada (de esta manera definitivamente no aparecerá en absoluto entre los resultados de búsqueda, a diferencia de un “Disallow” en el robots.txt).
* NoFollow, le indica al bot que no siga los enlaces de la página actual
* Los operadores follow, index y all no son necesarios ya que se asumen como activos en forma tácita
Si la etiqueta robots contiene información contradictoria (follow, nofollow) entonces el bot decidirá por si mismo que acción tomar.
La siguiente etiqueta en uno de nuestros posts, por ejemplo, indicaría a Google que no indexe ese post en particular, pero que siga los enlaces en el mismo:
[size=18pt][b]<meta name="robots" content="noindex,follow"> | <meta name="robots" content="noindex">[/b]
Existen, además, otros operadores para la sección “robots-terms”, que sin embargo no son muy utilizados. Ojo, no todos ellos son validados por todos los buscadores, algunos funcionan solo para los principales, o solo para Google, como es el caso del operador “Unavailable_After”, el cual le indica a Google que a partir de cierta fecha la página debe dejar de indexarse (útil para noticias u ocurrencias válidas solo para un determinado lapso de tiempo).
Finalmente, recomiendo infinitamente configurar adecuadamente un archivo robots.txt para su web o blog. Como se habrán dado cuenta, su utilidad es muy valisoa y sin embargo una gran cantidad de webs no tiene uno activo.
[right][size=24px][b]este post va para todo lo que no
entendieron lo que significaba la imagen de
este post: http://www.casitaweb.net/imagenes/ver/8806[/b]



3 Comentarios